RL Poker Bot
Overview
I built this poker bot after losing too much money in weekly poker games with friends. I wanted to understand what optimal play actually looks like, so I dove into Game Theory Optimal (GTO) strategies—mathematically balanced approaches that are theoretically unexploitable by opponents.
The Challenge
Creating a poker bot involves several distinct challenges: first, "seeing" and understanding the game state from screen pixels; second, developing a strategy that accounts for the probabilistic nature of card games; and third, making decisions that balance exploration (trying new strategies) with exploitation (using known effective strategies).
My Approach
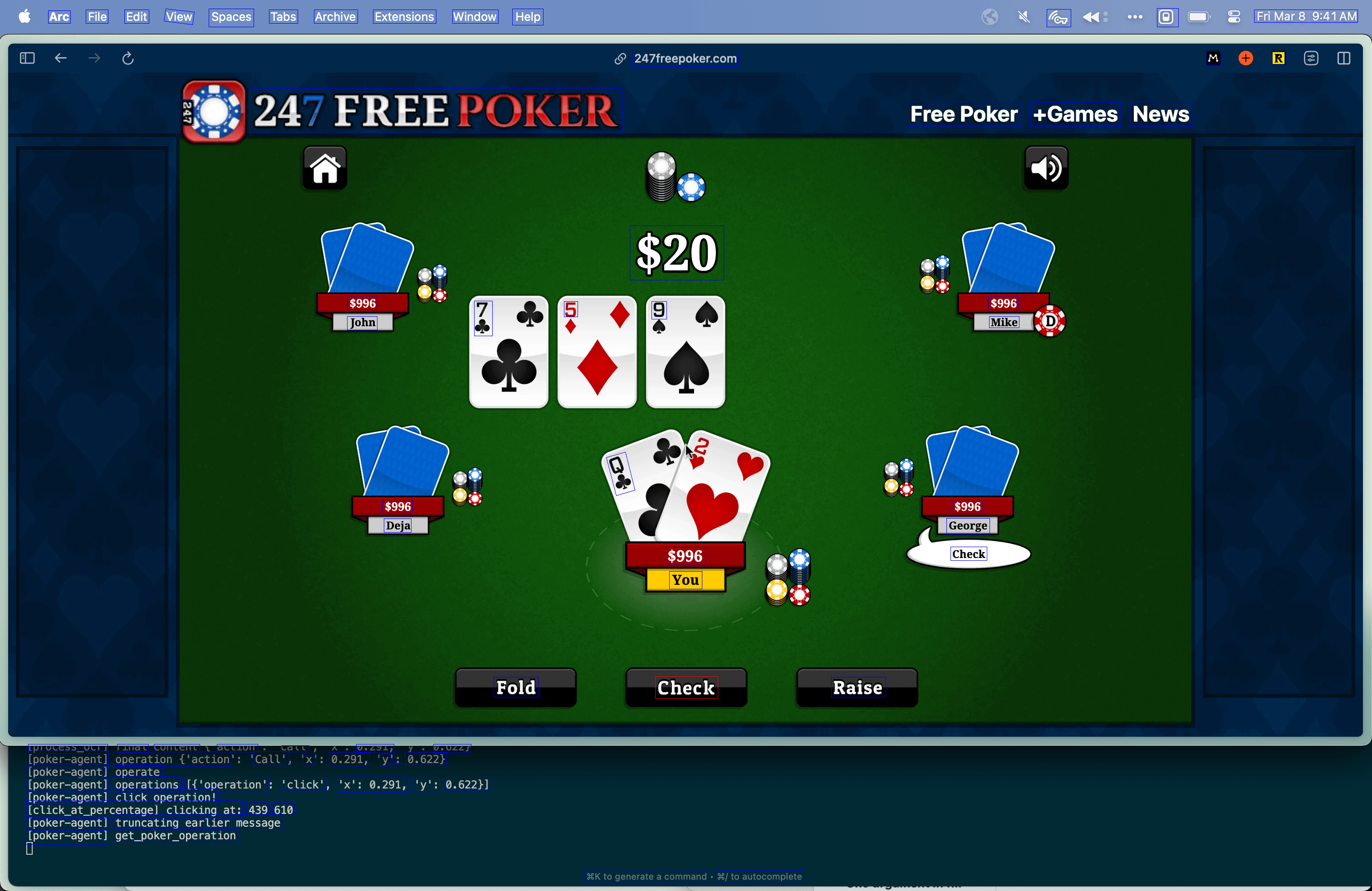
We built a system that uses GPT-V to extract game information from screenshots, parsing details like hole cards, community cards, pot size, and opponent actions. This data feeds into three different agent models: a fixed-strategy agent based on established poker heuristics, a random agent for baseline comparison, and a Deep Q-Network agent that learns optimal betting strategies through reinforcement learning.
The Solution
The final system operates autonomously on poker websites, making decisions based on real-time game state analysis. The DQN agent uses neural networks to approximate optimal betting strategies, while the fixed-strategy agent follows pre-programmed decision rules based on Game Theory Optimal (GTO) principles. We evaluated performance by running thousands of simulated hands between the different agents.
Technologies Used
Outcomes
After 1,000 hands of evaluation, our fixed-strategy model dominated with 927 wins, while the DQN agent won 51 hands. The random agent performed as expected with only 6 wins. These results highlighted the effectiveness of established poker heuristics, while showing the potential for reinforcement learning to develop novel strategies with sufficient training time.
Project Gallery